A community-driven Python library for bioinformatics, providing versatile data structures, algorithms and educational resources.
For Researchers
Robust, performant and scalable algorithms tailored for the vast landscape of biological data analysis spanning genomics, microbiomics, ecology, evolutionary biology and more. Built to unveil the insights hidden in complex, multi-omic data.
Example
from skbio.tree import TreeNode
from skbio.diversity import beta_diversity
from skbio.stats.ordination import pcoa
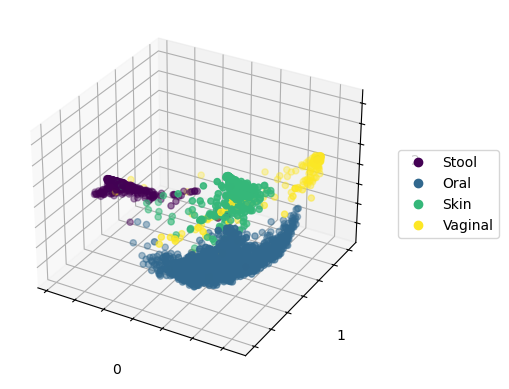
table = pd.read_table('data.tsv', index_col=0)
metadata = pd.read_table('metadata.tsv', index_col=0)
tree = TreeNode.read('tree.nwk')
bdiv = beta_diversity('weighted_unifrac', table, tree=tree)
ordi = pcoa(bdiv, dimensions=3)
ordi.plot(metadata, column='bodysite')
For Educators
Fundamental bioinformatics algorithms enriched by comprehensive documentation, examples and references, offering a rich resource for classroom and laboratory education (with proven success). Designed to spark curiosity and foster innovation.
For Developers
Industry-standard, production-ready Python codebase featuring a stable, unit-tested API that streamlines development and integration. Licensed under the 3-Clause BSD, it provides an expansive platform for both academic research and commercial ventures.
Install
conda install -c conda-forge scikit-bio
pip install scikit-bio
pip install git+https://github.com/scikit-bio/scikit-bio.git
See detailed instructions on installing scikit-bio on various platforms.
News
Latest release (2026-02-11):
scikit-bio is participating in Google Summer of Code 2026. Contributors are welcome!
scikit-bio paper published in Nature Methods. Full text available.
scikit-bio workshop at ISMB 2024. Materials are publicly available.
DOE grant for scikit-bio development in multi-omics and complex modeling.
New website: scikit.bio and organization: scikit-bio are online.
Feature Highlights
Biological sequences: Efficient data structure with a flexible grammar for easy manipulation, annotation, alignment, and conversion into motifs or k-mers for in-depth analysis.
Phylogenetic trees: Scalable tree structure tailored for evolutionary biology, supporting diverse operations in navigation, manipulation, comparison, and construction.